Prompt Engineering Mastery
Master advanced prompting techniques including Chain-of-Thought, Chain-of-Verification, and Tree-of-Thoughts. Learn to design effective prompts, optimize through testing, and build a library of reusable patterns.
Prompt Engineering Mastery
You have used AI. You have typed questions, gotten answers. Sometimes they are brilliant; sometimes they are nonsense. Often, the difference is not the AI. It is the prompt.
Prompt engineering is not about finding magic words. It is about understanding how language models process input and structuring that input to maximize the probability of useful outputs. This module teaches you the principles and techniques that separate effective prompts from ineffective ones.
Prompt Engineering Principles
When you call a function in code, you provide parameters in a specific format. The function does not guess what you mean. It processes exactly what you give it. Prompts work similarly, but the “function” is a probabilistic token predictor, not deterministic logic.
The practice of designing and refining inputs to language models to achieve desired outputs. It combines understanding of how models process text with systematic testing and iteration to produce reliable, consistent results.
This creates both challenges and opportunities.
The challenges include that the same prompt can produce different outputs, subtle wording changes can dramatically affect results, models may misinterpret intent or context, and there is no guarantee of factual accuracy.
The opportunities include that iterative refinement can dramatically improve outputs, structured approaches yield consistent results, you can “program” behavior through examples and instructions, and advanced techniques unlock reasoning capabilities.
Prompt as Programming
Consider this perspective: prompt engineering is a form of programming where your code is natural language, your compiler is a language model, your output is generated text, and your debugging is iterative testing.
Traditional programming gives you deterministic execution: the same input always produces the same output. Prompt programming gives you probabilistic generation: similar inputs tend to produce similar outputs, but variation is inherent. This requires different skills and expectations.
In traditional programming, you write a function like calculate_tax(income, rate) that returns income * rate. In prompt programming, you write something like “Given an income and tax rate, calculate the tax owed. Income: $50,000. Tax rate: 22%. Step by step:” Both specify inputs, operations, and expected outputs, but prompts work with a probabilistic system that requires different techniques.
The Prompt Engineering Mindset
Effective prompt engineering requires several key practices.
Precision means being specific about what you want. “Write a function” is vague. “Write a Python function that takes a list of integers and returns the median value, handling even-length lists correctly” is precise.
Experimentation recognizes that your first prompt rarely works perfectly. Expect to iterate.
Important
Always validate outputs. The model can sound confident while being completely wrong. Good prompts improve the odds of correct outputs but never guarantee them.
Verification means always validating outputs. The model can sound confident while being completely wrong.
Pattern recognition develops as you learn what works across different tasks and domains.
Documentation keeps track of effective prompts. Build a personal library.
The Anatomy of a Good Prompt
Effective prompts typically include several components.
Context provides background information the model needs. Instruction specifies what you want it to do. Input contains the specific data or query. Output format describes how you want the response structured. Constraints indicate what to avoid or emphasize. Examples provide few-shot demonstrations, which are optional but powerful.
Pro Tip
Not every prompt needs all components, but thinking in these terms helps structure your requests effectively. Start with context, instruction, and input, then add format and constraints as needed.
Foundational Techniques
The foundation of good prompting is clarity. Models are literal. They do what you ask, not what you mean.
Clear Instructions
A weak prompt says “Tell me about React hooks.” A strong prompt says “Explain React hooks to an experienced developer familiar with class components but new to hooks. Focus on useState and useEffect. Include what problems hooks solve, basic syntax with code examples, common mistakes to avoid, and when to use each hook.”
The strong prompt specifies audience, scope, structure, and emphasis.
Providing Context
Models have no memory beyond the conversation. Every prompt exists in isolation unless you provide context.
Without context, asking “How do I fix this error?” is essentially unanswerable. With context, explaining that you are building a Node.js Express API, getting a specific error when querying PostgreSQL, providing your connection code, and specifying your environment transforms an impossible question into an answerable one.
Context transforms vague questions into answerable ones. The more relevant context you provide, the more useful the response will be. But avoid overwhelming the model with irrelevant details.
Role Assignment
Giving the model a role can improve outputs by activating relevant patterns from training data.
Effective roles include “You are a senior code reviewer for a Python project following PEP 8 standards” or “You are an experienced DevOps engineer specializing in Kubernetes.”
This works because training data likely contains many examples of experts explaining concepts. The role primes the model to match those patterns.
A prompting technique where you specify a persona or expertise level for the model to adopt, activating relevant patterns from training data. Effective roles are specific, domain-relevant, and establish clear expertise or perspective.
Ineffective roles include overly creative ones like “You are a time-traveling wizard who codes,” contradictory ones like “You are always right and never make mistakes,” or too vague ones like “You are helpful.”
Few-Shot Learning
Instead of describing what you want, show examples. This is called few-shot prompting.
Zero-shot provides only instruction without examples. Few-shot provides instruction with examples that demonstrate the desired behavior.
Pro Tip
Few-shot learning is powerful because it shows rather than tells, handles edge cases through examples, establishes patterns the model can follow, and works across domains. Two or three well-chosen examples often improve results more than lengthy instructions.
For a task like converting sentences to title case while preserving lowercase for articles and prepositions, showing examples like “the quick brown fox jumps over the lazy dog” becoming “The Quick Brown Fox Jumps Over the Lazy Dog” teaches the pattern more effectively than describing the rules.
Output Format Specification
Tell the model exactly how to structure its response.
Unstructured requests often produce inconsistent formats. Structured requests that specify JSON schema, markdown structure, or specific field requirements make outputs parseable, consistent, and actionable.
Common formats include JSON for structured data, markdown for documentation, code blocks for implementations, lists for options or steps, and tables for comparisons.
Chain Breaking for Complex Tasks
Do not ask the model to do everything at once. Break complex tasks into steps.
Important
Monolithic prompts that request complete systems with authentication, database models, and tests are prone to failure. Chain prompts that build incrementally, verifying each step before proceeding, are more reliable.
A monolithic prompt requesting “a complete REST API for a blog with users, posts, and comments, including authentication, database models, and tests” will often fail. A chained approach that first designs the schema, then creates models based on that schema, then builds endpoints based on those models, produces better results because each step can be verified before proceeding.
Chain-of-Thought Prompting
Chain-of-Thought prompting encourages models to show their reasoning process rather than jumping directly to answers. This improves accuracy, especially for tasks requiring multiple reasoning steps.
A prompting technique that elicits step-by-step reasoning from language models. By asking models to show their work, CoT improves accuracy on complex tasks by creating intermediate checkpoints and activating reasoning patterns from training data.
Why CoT Works
When you ask for reasoning steps, several things happen.
Better token predictions result because training data contains more correct answers that show work than correct answers alone. Intermediate checkpoints constrain subsequent steps, each reasoning step narrowing the solution space. Error detection becomes possible because wrong reasoning is often more obvious than wrong answers. Training patterns are leveraged because educational content and technical documentation frequently show step-by-step reasoning.
Standard Chain-of-Thought
The basic CoT structure presents a problem and adds “Let’s solve this step by step” or similar phrasing. The model then generates numbered steps that walk through the reasoning before arriving at a final answer.
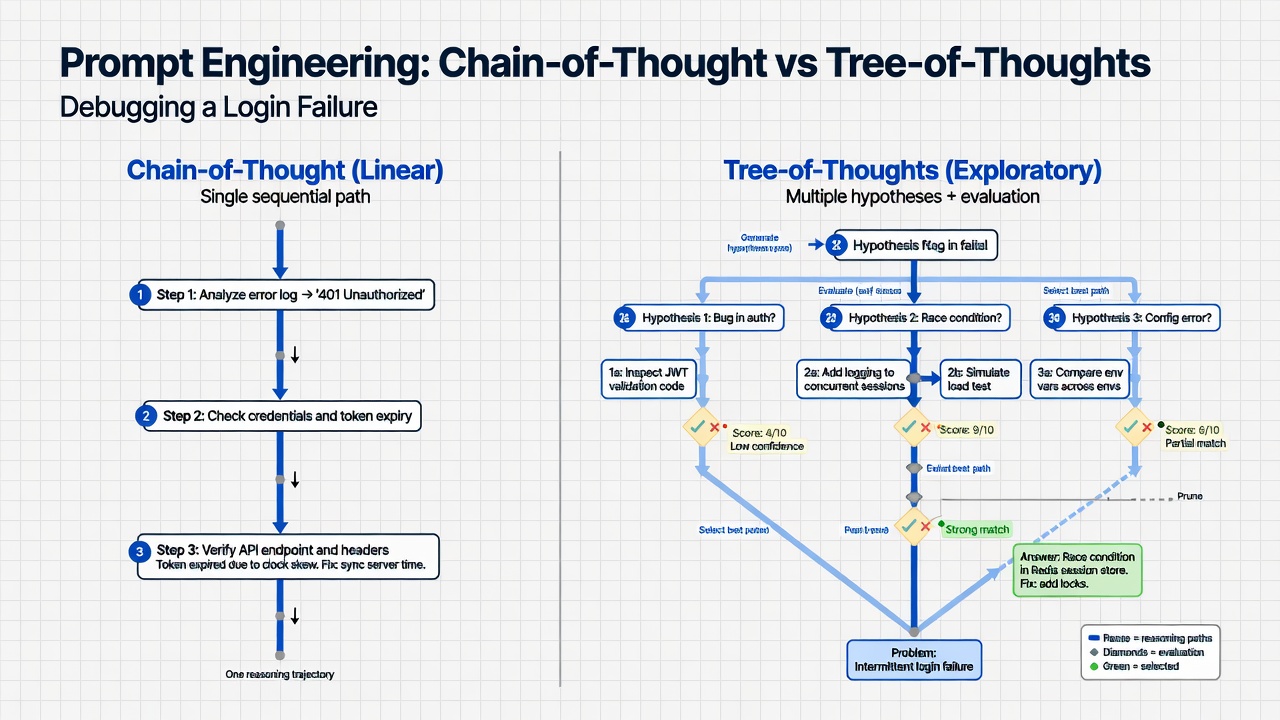
Tree-of-Thoughts extends CoT by exploring multiple reasoning paths in parallel and evaluating them, improving performance on hard problems.
Remarkably, simply adding “Let’s think step by step” often triggers reasoning without any examples. This zero-shot CoT works because the phrase appears in training data associated with correct reasoning processes.
When CoT Helps Most
Chain-of-Thought is particularly effective for mathematical reasoning with multi-step calculations, logical deduction requiring inference from premises, multi-step procedures like debugging by tracing execution, and complex comparisons requiring systematic evaluation of multiple factors.
When CoT May Not Help
CoT is less useful or even counterproductive for simple fact retrieval, pattern completion tasks, creative generation where flow matters more than logic, and tasks requiring conciseness like summaries or headlines. The overhead of reasoning steps outweighs benefits for simple queries.
Structured CoT Templates
For consistent results, provide a reasoning structure. Instead of letting the model choose its reasoning format, specify the analysis framework. For code review, you might specify steps like “What does the current code do?” then “What does the new code do?” then “What are the differences?” then “What depends on the changed behavior?” then “Conclusion: Breaking or non-breaking?”
Pro Tip
Combining CoT with few-shot learning is particularly effective. Show examples of the reasoning pattern you want, then ask the model to apply the same pattern to new inputs.
Chain-of-Verification
Language models hallucinate, generating confident falsehoods. Chain-of-Verification is a technique to reduce this by having the model verify its own outputs.
The key insight is that models are often better at verification than generation. A model might incorrectly claim “Python was released in 1995” but correctly answer “Was Python released in 1995?” with “No, it was first released in 1991.”
A technique that reduces hallucinations by having the model verify its own outputs. The model generates an initial response, creates verification questions, answers those questions, and produces a revised response incorporating any corrections.
Basic CoV Pattern
The structure is straightforward. Generate an initial response. Generate verification questions about that response. Answer the verification questions. Produce a final revised response based on verification.
Self-Consistency Checking
Ask the model to solve problems multiple times using different approaches, then reconcile. For calculating time complexity, you might use operation counting, recurrence relations, and comparison to known patterns, then check if all approaches agree. Disagreement between approaches signals potential errors.
Important
Chain-of-Verification has limits. If the model does not know something, verification will not help. Models can verify incorrect information confidently. For critical information, verify against actual sources, not model self-checking.
Limitations of CoV
Chain-of-Verification has important limits. Same model, same biases means that if the model does not know something, verification will not help. Overconfidence means models can verify incorrect information confidently. Computational cost means multiple generation steps increase latency and token usage. Not a substitute for real verification means critical information needs external verification.
Use CoV when factual accuracy is important but not mission-critical, when you are generating technical content that can be verified logically, when the cost of hallucinations is moderate, and when you cannot easily verify outputs yourself.
Reflection and Self-Correction
While CoV focuses on factual verification, reflection techniques ask models to critique the quality of their outputs: clarity, completeness, adherence to requirements.
The Self-Critique Pattern
Generate initial output, then evaluate on specific dimensions like clarity, completeness, examples, and accuracy. Rate each dimension and explain deficiencies. Revise based on the critique.
Pro Tip
Multiple perspectives often catch issues single-perspective analysis misses. Have the model review from different roles: security reviewer, performance engineer, maintainability advocate. Then synthesize the findings.
The “What Could Go Wrong” Technique
Ask the model to explicitly consider failure modes. For system design, generate the design, then analyze what happens if various components fail: service unavailable, database fails mid-transaction, extreme load, unreliable network, inconsistent data. Then revise the design to address these concerns.
This “pre-mortem” approach improves robustness.
Limitations of Self-Correction
Models have inherent limitations in self-correction. They cannot fix unknown unknowns. They may double-down on errors. They have limited meta-cognition. Diminishing returns set in beyond two or three rounds. The process is still probabilistic.
To maximize effectiveness, be specific about evaluation criteria, use concrete examples in critique, limit reflection rounds to two or three, verify critical outputs externally, and compare before and after since sometimes the original is better than the “improved” version.
Tree-of-Thoughts and Beyond
Chain-of-Thought follows a single reasoning path. But complex problems often require exploring multiple paths before committing to one. Tree-of-Thoughts enables this exploration.
A reasoning framework that generates multiple solution approaches, evaluates each, and pursues the most promising ones. Unlike linear Chain-of-Thought, ToT enables exploration and backtracking, similar to beam search for reasoning.
Basic Tree-of-Thoughts Structure
Generate multiple approaches to a problem. Evaluate each approach on relevant criteria. Select the most promising approaches. Develop the selected approaches in detail. Make a final comparison and recommendation.
When ToT is Valuable
Tree-of-Thoughts shines for problems with multiple viable approaches, optimization problems requiring comparison of different strategies, and creative tasks requiring exploration before committing to a direction.
Pruning Strategies
ToT can explode combinatorially. Use pruning to stay manageable.
Evaluation-based pruning generates many solutions but pursues only the top performers. Constraint-based pruning discards any solutions that violate requirements. Threshold-based pruning pursues only those scoring above a minimum threshold.
Important
Tree-of-Thoughts has significant downsides: computational cost (potentially 10x tokens for a simple question), latency from sequential generation, complexity in prompt design, and diminishing returns for simple problems. Use ToT selectively for complex, high-value problems.
Combining Techniques
The most powerful prompts combine multiple techniques. For debugging a distributed system, you might use ToT to generate multiple hypotheses, CoT to trace through each hypothesis systematically, and CoV to verify the most likely cause before finalizing diagnosis and solution.
Practical Prompt Optimization
Prompt engineering is empirical. What works must be tested, not assumed.
Systematic Testing
Create test cases covering easy, moderate, hard, and edge cases. Run your prompt against all test cases. Measure specific characteristics of outputs.
Pro Tip
Treat prompts like code: version them. Track the version number, date, changes made, performance metrics, and remaining issues. This history helps you understand what improvements work.
A/B Testing Prompts
Compare variations systematically. Test a basic prompt, one with added structure, and one with role assignment, examples, and explicit format requirements. Run each against the same inputs and compare which catches more issues, produces better quality, and is more consistent.
Iteration Workflow
Start simple with a basic prompt. Test against diverse inputs. Identify where it fails. Hypothesize why it failed. Make targeted modifications. Test again to see if it improved. Repeat until good enough.
Common Improvements
When prompts underperform, try adding specificity (from “Write a function” to “Write a Python function with type hints that…”), adding structure (from “Review this code” to “Review this code for: 1) bugs, 2) security, 3) performance”), adding examples, adding constraints, or adding explicit output format.
Performance Metrics
Define what “good” means for your use case. Accuracy measures whether it gives correct information. Completeness measures whether it covers all requirements. Conciseness measures whether it is the right length. Format adherence measures whether it follows the requested structure. Consistency measures whether similar inputs produce similar outputs.
Prompt Patterns Library
Here is a library of reusable prompt patterns for common scenarios.
Pattern: Role-Task-Format
“You are [ROLE]. Your task is to [TASK]. Provide your response as [FORMAT].”
Pattern: Few-Shot with CoT
Provide task description, then examples showing input, reasoning steps, and output. Then present the actual input and ask for reasoning.
Building a personal prompt library accelerates your work. Save effective prompts, generalize them into templates, document when each works best, share and iterate with your team, and version control changes.
Pattern: Generate-Critique-Revise
Generate initial output. Critique on specific criteria. Revise based on the critique.
Pattern: Explore-Evaluate-Select
Generate multiple approaches. Evaluate each on defined criteria. Select the best and develop in detail.
Pattern: Context-Question-Constraints
Provide all relevant background. Ask the specific question. List constraints. Optionally specify output format.
Domain-Specific Patterns
For code review, specify the language, list what to review for (correctness, security, performance, maintainability, best practices), and for each issue require line numbers, severity, explanation, and suggested fix.
For debugging, provide symptoms, expected behavior, code, and environment. Then structure step-by-step debugging: likely cause, verification approach, fix, and alternative explanations.
For documentation, specify the type, include overview, usage with examples, parameters, return values, examples, edge cases and errors, and notes.
Diagrams
Prompt Engineering Techniques Hierarchy
graph TD
A[Prompt Engineering] --> B[Foundational]
A --> C[Reasoning]
A --> D[Verification]
A --> E[Exploration]
B --> B1[Clear Instructions]
B --> B2[Context]
B --> B3[Roles]
B --> B4[Few-Shot]
B --> B5[Format]
C --> C1[Chain-of-Thought]
C --> C2[Zero-Shot CoT]
C --> C3[Structured Reasoning]
D --> D1[Chain-of-Verification]
D --> D2[Self-Consistency]
D --> D3[Self-Critique]
E --> E1[Tree-of-Thoughts]
E --> E2[Branch Exploration]
E --> E3[Pruning]
Chain-of-Thought Flow
graph LR
A[Problem] --> B[Step by Step]
B --> C[Analyze]
C --> D[Reason]
D --> E[Calculate]
E --> F[Conclude]
F --> G[Answer]
style B fill:#c8e6c9
style G fill:#c8e6c9
Chain-of-Verification Process
graph TD
A[Query] --> B[Generate Response]
B --> C[Generate Questions]
C --> D[Answer Questions]
D --> E{Inconsistencies?}
E -->|Yes| F[Revise]
E -->|No| G[Return]
F --> H[Final Response]
style E fill:#fff9c4
style G fill:#c8e6c9
style H fill:#c8e6c9
Tree-of-Thoughts Structure
graph TD
A[Problem] --> B[Generate Approaches]
B --> C1[Approach 1]
B --> C2[Approach 2]
B --> C3[Approach 3]
C1 -->|Score: 8| D1[Develop]
C2 -->|Score: 5| X1[Prune]
C3 -->|Score: 9| D2[Develop]
D1 --> F[Compare]
D2 --> F
F --> G[Best Solution]
style D1 fill:#c8e6c9
style D2 fill:#c8e6c9
style X1 fill:#ffcdd2
style G fill:#c8e6c9
Prompt Optimization Cycle
graph LR
A[Initial Prompt] --> B[Test]
B --> C[Identify Failures]
C --> D[Analyze Why]
D --> E[Modify]
E --> F{Good Enough?}
F -->|No| B
F -->|Yes| G[Deploy]
style F fill:#fff9c4
style G fill:#c8e6c9
Hands-On Exercise
Knowledge Check
Summary
In this module, you learned that prompt engineering is a skill combining understanding of language models, systematic testing, and iterative refinement.
Foundational techniques including clear instructions, context, roles, few-shot learning, and format specification form the base of effective prompting. These techniques work because they help models match relevant patterns from training data.
Chain-of-Thought improves reasoning by eliciting step-by-step thinking, especially for complex multi-step problems. Zero-shot CoT often works by simply adding “Let’s think step by step.”
Chain-of-Verification reduces hallucinations by having models verify their own outputs. However, it is not a substitute for external verification on critical information.
Reflection and self-critique can improve output quality through iterative refinement, with diminishing returns after two or three rounds. Multiple perspectives often catch issues single-perspective analysis misses.
Tree-of-Thoughts enables exploration of multiple solution paths, valuable for complex problems but costly for simple ones. Use ToT selectively where the exploration value justifies the computational cost.
Systematic optimization through testing, versioning, and iteration is essential for production-quality prompts. Treat prompts like code.
Reusable patterns accelerate your work and encode best practices. Build a personal library of effective prompts.
The key insight is that prompts are not magic incantations. They are interfaces to probabilistic systems. Understanding both the system and the interface lets you engineer reliable outputs.
What’s Next
In the next module, we will explore AI agents architecture. We will cover what makes an agent different from a chatbot, the agent loop of perceive-reason-act, tool use and function calling, memory systems, and agent patterns. The prompt engineering skills from this module are the foundation of agent behavior.
References
Academic Papers
-
Wei, J., et al. (2022). “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” Google. The foundational paper demonstrating CoT’s effectiveness. arxiv.org/abs/2201.11903
-
Yao, S., et al. (2023). “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” Introduces ToT framework for exploring multiple reasoning paths. arxiv.org/abs/2305.10601
-
Dhuliawala, S., et al. (2023). “Chain-of-Verification Reduces Hallucination in Large Language Models.” Meta. Proposes CoV method for reducing hallucinations. arxiv.org/abs/2309.11495
-
Shinn, N., et al. (2023). “Reflexion: Language Agents with Verbal Reinforcement Learning.” Explores self-reflection and iterative improvement. arxiv.org/abs/2303.11366
Official Documentation
-
Anthropic Prompt Engineering Guide. Comprehensive guide to prompting Claude effectively. docs.anthropic.com/en/docs/build-with-claude/prompt-engineering
-
OpenAI Prompt Engineering Guide. Official OpenAI guidance on GPT model prompting. platform.openai.com/docs/guides/prompt-engineering
Practical Resources
-
Prompt Engineering Guide (DAIR.AI). Community-maintained comprehensive guide covering techniques, papers, and examples. promptingguide.ai
-
LangChain Prompt Templates. Library of reusable prompt patterns for common tasks. python.langchain.com/docs/modules/model_io/prompts